The OpenHands Index: 3 Months Out

Written by
Rajiv Shah
Published on
Skills are becoming a core building block for AI coding agents. Research is documenting their value. For example, SkillsBench found large gains across a broad task set. At OpenHands, we also recently wrote about how to create effective agent skills.
But a useful skill is not just something that sounds smart. It is something that measurably improves outcomes on a real task. Some skills are transformative. Some are just guardrails. Some actually make the agent worse.
This post and accompanying repo look at the other side of the problem: how to evaluate whether a skill is helping at all.
If skills just codify knowledge, why bother evaluating them?
Because poorly written skills can reduce performance. In SkillsBench, most skills helped, but some produced negative deltas. In other words, the added guidance made the model less effective, not more.
There is a second reason too: as models improve, some skills stop mattering. Boris Cherny, a developer on Claude Code, put it this way:
"The capability changes with every model. The thing that you want is do the minimal possible thing in order to get the model on track. Delete your claude.md and then, if the model gets off track, add back a little bit at a time. What you're probably going to find is with every model you have to add less and less."
And finally, skills are model-dependent. A workflow that helps one model may be unnecessary, or harmful, for another.
That is why evaluation matters. "Improved skill" is just a hypothesis until it is measured.
A good skill evaluation has three ingredients:
So the minimum comparison is:
To make this concrete, I built the evaluating-skills-tutorial repo. It contains:
three deterministic tasks
a no-skill baseline and an improved skill for each task
local verifiers
scripts to run evaluations on OpenHands Cloud or a local agent server
saved result summaries you can inspect and reproduce We ran the tasks across five models:
Claude Sonnet 4.5
Gemini 3 Pro
Gemini 3 Flash
Kimi K2
MiniMax M2.5 The point was not to produce one grand benchmark number. It was to show how different tasks reveal different kinds of skill value.
The first task asks the agent to inspect a package-lock.json and produce a report.json containing only HIGH and CRITICAL vulnerabilities.
This task is procedural. Without guidance, agents tend to improvise: they try different scanners, refresh vulnerability databases, or include findings that should have been filtered out.
The improved skill fixes that by encoding a specific workflow:
| Condition | Pass Rate | Avg Runtime | Avg Events |
|---|---|---|---|
| No-skill | 0% (0/10) | 266s | 53 |
| Improved-skill | 100% (10/10) | 109s | 22 |
This is the clearest example of a high-value skill. It does not just polish the output. It teaches the agent the actual workflow the task requires.
The second task asks the agent to read two quarterly financial reports and write a structured answers.json with extracted metrics and derived percentages.
Most strong models can already do this kind of task. The data is right there in the files. So the skill is not unlocking a hidden capability.
Instead, the improved skill adds:
| Condition | Pass Rate | Avg Runtime |
|---|---|---|
| No-skill | 90% (9/10) | 87s |
| Improved-skill | 100% (10/10) | 99s |
This is a different pattern. The skill helps with consistency more than capability. It acts as a guardrail and reduces the chance that one model gets the arithmetic or workflow slightly wrong.
The third task asks the agent to combine an Excel workbook and a PDF into a new workbook with two sheets: CombinedData and Summary.
This skill provides a detailed no-install parsing path using Python built-ins like zipfile and xml.etree.ElementTree, plus exact sheet-structure requirements.
The overall result looks mildly positive:
| Condition | Pass Rate |
|---|---|
| No-skill | 70% (7/10) |
| Improved-skill | 80% (8/10) |
But that aggregate number hides the interesting part: the effect varies by model and backend.
These three tasks produce three different conclusions:
If you only tested the dependency audit, you would conclude that skills are transformative.
If you only tested the financial report, you might conclude they are modest quality-of-life improvements.
If you only tested the sales pivot task, you might conclude skills are overengineering.
All three conclusions would be incomplete.
The right takeaway is that skill quality is task-dependent and model-dependent.
Pass/fail tells you whether the skill worked. Traces tell you why.
When you inspect traces, you can often see patterns like:
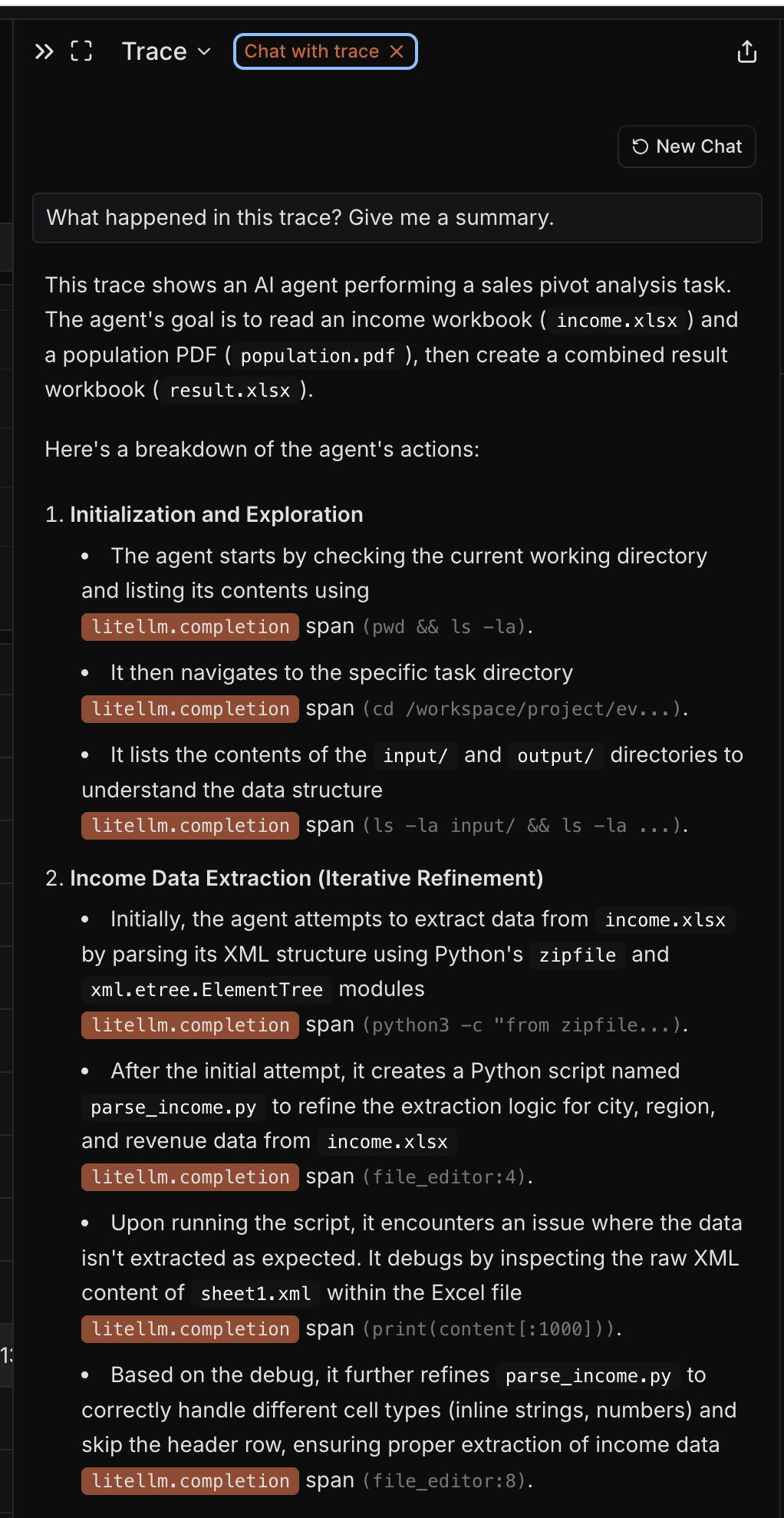
That makes traces especially useful for improving a skill after the first round of evaluation. The verifier tells you whether you won or lost; the trace helps you understand what to fix.
In the tutorial repo, we used Laminar for observability, but the evaluation loop is not tied to one tracing stack. OpenHands is OTEL-compatible, so you can plug in whatever observability system you prefer.
If you want to test whether a skill actually helps, use a loop like this:
You do not need a huge benchmark to start. A small number of carefully designed tasks is often enough to show whether your skill is adding real value.
The full repo is available here:
The main point of the project is simple:
Do not assume a skill is helping just because it exists. Measure it.
This tutorial was inspired by SkillsBench and adapts its core idea of evaluating skills on deterministic tasks with local verifiers.
Insights and updates from the OpenHands team
Sign up for our newsletter for updates, events, and community insights.
_1.svg)
OpenHands is the foundation for secure, transparent, model-agnostic coding agents - empowering every software team to build faster with full control.